
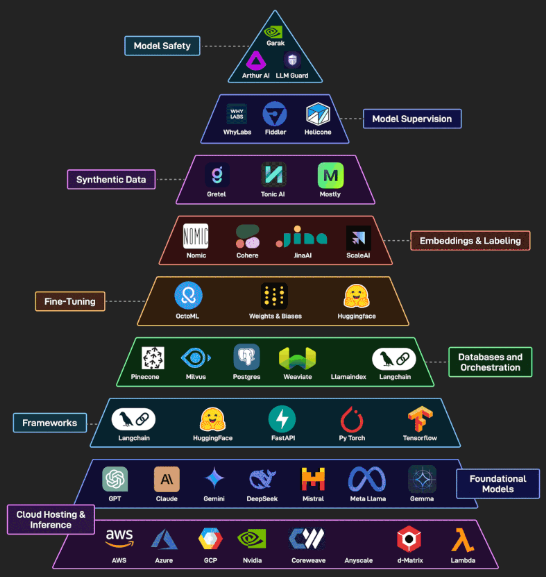
When I first dipped my toes into generative AI, it felt like standing at the base of a vast mountain range. As a machine learning engineer focused on fraud detection, I’d spent years building graph models with Kubeflow and Kubernetes—so stepping into the world of large language models was exhilarating (and a bit daunting). Over time, I learned to conquer each “peak” of the generative AI tech stack. Here’s how the layers fit together.
1. Cloud Hosting & Inference
Cloud providers and GPU-as-a-service platforms (AWS, Azure, GCP, NVIDIA Cloud, CoreWeave, Anyscale, d-Matrix, Lambda Labs) form the foundation for deploying and scaling generative AI workloads. They offer managed compute, autoscaling, and pay-as-you-go pricing so teams can spin up GPU clusters or specialized inference endpoints on demand, minimizing ops overhead and ensuring high availability.
Lessons Learned: Be ready to compare at least two providers’ pros and cons (e.g., cold start latency, region availability, cost per GPU-hour) and come up with a deployment architecture you’d choose for your production model.
2. Foundational Models
Large pre-trained models (OpenAI GPT, Anthropic Claude, Google Gemini, Mistral, Meta Llama, Gemma, etc.) provide the “brains” of generative AI systems. They encapsulate vast world knowledge and language skills, enabling text generation, code synthesis, and more with minimal task-specific training. Choosing the right base model involves balancing capabilities, latency, fine-tuning support, and licensing.
Lessons Learned: Pick two open-source and one proprietary foundation model, and be prepared to benchmark them (e.g., perplexity, response time, cost) for a your use case.
3. Frameworks
Frameworks like LangChain, HuggingFace’s Transformers and Datasets, FastAPI, PyTorch, and TensorFlow provide the libraries and abstractions needed to build, serve, and integrate generative models into applications. They streamline everything from data pipelines and prompt chaining to RESTful inference APIs, drastically reducing boilerplate and accelerating iteration.
Lessons Learned: Start with a mini project where you used a framework (e.g., LangChain for prompt orchestration or FastAPI for serving), check how it would save development time or improve maintainability.

4. Databases & Orchestration
Vector databases and orchestration tools (Pinecone, Milvus, PostgreSQL + pgvector, Weaviate, LlamaIndex, LangChain orchestrators) manage embeddings and retrieval-augmented generation (RAG) workflows. They index high-dimensional vectors, support k-NN search at scale, and coordinate multi-step pipelines to fuse LLM outputs with external knowledge stores.
Lessons Learned: Learn the end-to-end flow of a RAG system—how you’d embed documents, index them, retrieve relevant context, and inject it into prompts? Choose a specific database with your business metics.
5. Fine-Tuning
Platforms like OctoML, Weights & Biases, and Hugging Face’s Trainer offer tools for adapting base models to custom datasets. They handle hyperparameter tracking, distributed training, parameter-efficient tuning (PEFT), and experiment management, ensuring reproducible, efficient fine-tuning that maximizes model performance on domain-specific tasks.
Lessons Learned: For a fine-tuning experiment you’ve run, make sure you learned how you split data, selected learning rates or LoRA ranks, and monitored validation metrics to avoid overfitting.
6. Embeddings & Labeling
Services such as Nomic, Cohere Embeddings, Jina AI, and Scale AI help generate, refine, and label vector representations of text, images, or other modalities. High-quality embeddings are critical for semantic search, clustering, and downstream tasks, while labeling platforms streamline the creation of ground-truth data for supervised fine-tuning and evaluation.
Lessons Learned: Evaluate embedding quality (e.g., through silhouette scores or retrieval accuracy) and understand how active learning can optimize labeling budgets.
7. Synthetic Data
Synthetic-data generators like Gretel, Tonic AI, and Mostly allow teams to create realistic, privacy-preserving datasets for training and testing. They simulate patterns in tabular, time-series, or text data, helping to alleviate data scarcity, balance classes, and protect sensitive information without compromising model fidelity.
Lessons Learned: Use synthetic data to improve model robustness—e.g., augmenting rare classes or stress-testing edge cases—and validate its utility against real data.

8. Model Supervision
Tools like WhyLabs, Fiddler, and Helicone provide monitoring, drift detection, and explainability for production models. They track input distributions, output quality, and fairness metrics, alerting teams to anomalies, performance degradation, or unintended biases so issues can be diagnosed and addressed proactively.
Lessons Learned: Come up with a monitoring strategy for a deployed LLM—Metrics that you’d collect, thresholds you’d set, and remediation steps you’d take if drift or bias is detected.
9. Model Safety
Safety-focused layers (Garak, Arthur AI, LLM Guard) enforce guardrails, content filters, and adversarial testing to ensure generative models behave responsibly. They can intercept harmful or disallowed outputs, apply policy enforcement, and simulate attack scenarios to harden models against misuse.
Lessons Learned: Classify toxic responses, the role of human review, and define ways to integrate real-time filtering into your inference pipeline.
Conclusion
Climbing the generative AI stack felt like scaling Everest—each layer demanded its own toolkit and expertise. Whether you’re just provisioning GPUs or fine-tuning cutting-edge models, remember that each level builds on the last. Start at the bottom, learn step by step—and soon you’ll be planting your flag at the summit.
Recommended Reading List:
- AI Engineering by Chip Huyen – Amazon Link
- LLM Engineer’s Handbook by Paul Iusztin, et al – Amazon Link
- Build a Large Language Model by Sebastian Raschka – Amazon Link